Building-and-Aligning-LLM-using-User-Data-and-RL
Building and Aligning a Dialogue LLM with User Data and RL
This blog walks through an end-to-end alignment stack for an open-ended dialogue model: from low-level training stability in Mixture-of-Experts (MoE) to FP8 serving, supervised fine-tuning (SFT) on user chats, and finally reinforcement learning (RL) driven by engagement and retention signals.
Authors
Feel free to connect with us on LinkedIn for discussions about RL, AI assistants, and ML infrastructure!
This blog covers:
- Gradient synchronization in expert-parallel MoE
- FP16 vs FP8 for serving and quantization-aware training
- Using user “swipes” as rejection-sampling style SFT data
- Leveraging noisy user feedback for PPO-style RL
- Reward modeling from engagement and retention signals
- Practicalities of offline RL and long-horizon rewards
1. Stabilizing Expert-Parallel MoE Training
When using expert parallelism in a MoE architecture, some parameters are replicated within an expert parallel group. This introduces a subtle issue: their gradients can diverge if not explicitly synchronized.
To fix this, explicit gradient reduction hooks are added in the backward pass of the MoE layer. These hooks ensure that for parameters replicated across the expert parallel group, gradients are synced (e.g., via an all-reduce) every backward step.
Internal experiments compare training curves with proper gradient synchronization (for positional embeddings and expert parallel group) and without gradient sync. Without gradient synchronization:
- Gradient norms explode, clearly visible when plotting the gradient norm.
- Training becomes unstable, and
- The loss curve is consistently worse (higher) than the synchronized setup.
This simple but critical fix—adding backward hooks for replicated parameters—was necessary to make MoE training stable.
2. Making Serving Affordable: FP16 vs FP8
A major practical issue is that a pure FP16 (bf16 / fp16) training and serving stack can be extremely expensive at inference time.
- The FP16 version of large models requires multiple nodes just to serve a single instance.
- Inter-node communication is significantly slower than intra-node communication, which further hurts latency and throughput.
In contrast, an FP8 version of the model can fit on a single node, dramatically improving serving efficiency.
Exporting Fine-Tuned Checkpoints to FP8
Exporting fine-tuned checkpoints to FP8 can be done using a block-wise quantization algorithm [1, 2].
Key observations:
- Naive export-time quantization (post-training)—simply taking an FP16 checkpoint and quantizing it to FP8—can largely erase the benefits of fine-tuning.
- Without quantization-aware training (QAT), the FP8 model performance drops noticeably.
To address this, FP8 mixed-precision preserving training can be implemented, following the strategy described in DeepSeek-V3 Technical Report [3], as shown in the figure. The core idea is to train with FP8 in the loop instead of quantizing only at the end. The key setup in mixed precision AdamW is: master weights in FP32, forward/backward passes and gradients in BF16, while native PyTorch Adam forces optimizer states to be in the same precision as parameter dtype.
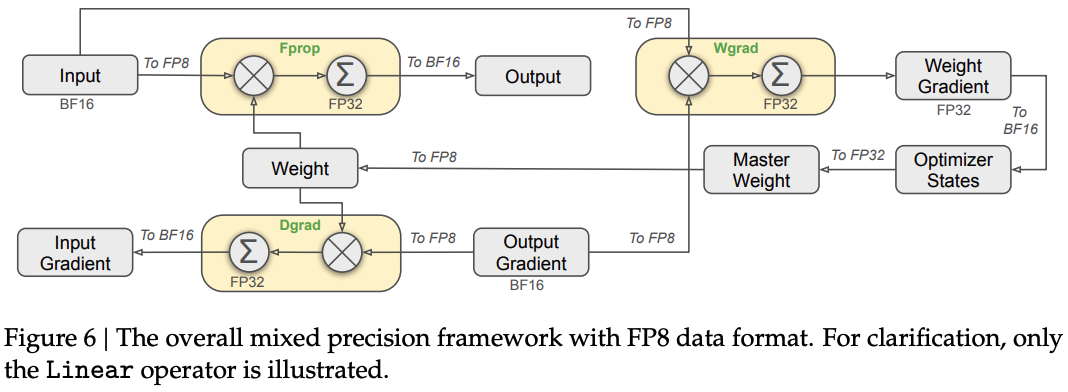
Using FP8 GEMM with FP32 Accumulation
To support FP8 training efficiently, an FP8 GEMM library [4] can be used:
- It provides efficient FP8 matrix multiplications,
- With FP32 accumulation to mitigate precision loss.
However, this library only accelerates the matrix multiplication kernels themselves.
The Performance Problem: Unfused Quantization
A full FP8 linear layer does more than just a GEMM—there is:
- Quantization and dequantization of weights
- Quantization and dequantization of activations
- Possible scaling, clipping, etc.
In the naive implementation:
- These quantization steps are not fused with the GEMM.
- As a result, a custom FP8
Linearlayer can be roughly 10× slower than the native PyTorch bf16Linearlayer.
To fix this, a custom fused FP8 linear layer can be implemented, combining quantization, dequantization, and matrix multiplication more tightly so FP8 training and serving become practical, not just numerically feasible.
3. Supervised Fine-Tuning on User Chats
One concrete use case in the alignment stack is supervised fine-tuning (SFT) on user chats.
The “Swipes/Votes” Feature as Supervision
One key interaction pattern in dialogue systems is swipes or votes, like what can be seen in ChatGPT or Gemini. This feature enables DPO training.
- When the model generates a response, users can swipe to request alternative responses or vote for a preferred response
- They then choose one response to continue the conversation.
This creates a highly engaged user base, which in turn generates a huge amount of swipe data/preference data—on the order of hundreds of billions of tokens of swipe/vote interactions per day. With some quality filtering, this approach uses:
- The chosen response from each swipe/vote set as supervised data.
-
This acts like user-guided rejection sampling:
- Multiple candidate responses exist,
- The user selects the best one,
- That selection is treated as the positive example.
Rejection sampling is known to improve model performance across many tasks; here, user swipes/votes implement a kind of implicit rejection sampling at scale. The “choose after swipe/vote” event is also an important reward signal that can be reused in RL.
4. Distillation to Cheaper Models and PPO Training
Another major use case for user chat data is distillation:
- Users can interact with larger or more exclusive (expensive) models.
- Those behaviors can then be distilled into smaller, more cost-efficient models.
When using user chat data for this distillation, key findings include:
- Filtering low-quality conversations is crucial.
- Ensuring data diversity is equally important so the student model doesn’t overfit to a narrow slice of behaviors.
Beyond SFT: PPO with User Data
In addition to SFT, user data can be leveraged for PPO-style RL training.
The signals include:
-
User-selected data
- The chosen swipe/vote response, as described above.
-
User preference data
- Explicit preference labels where users indicate which response they prefer.
-
Synthetic preference data
- Constructed to target known issues of the model, based on user feedback.
However, user preference data is inherently noisy, so substantial filtering is needed before using it.
Filtering Noisy User Preference Data
Some of the filtering strategies used include:
-
Limiting individual user influence Avoid letting a small set of highly active users dominate the training signal.
-
Filtering over-repeated conversations Avoid conversations that users trigger “too often” or look bot-like.
-
Requiring minimum reading time Ensure users spend enough time reading messages before making a choice; otherwise, their signal may not reflect genuine preference.
These heuristics are combined with other filters to construct a cleaner preference dataset for PPO.
At this point, the fine-tuning stack has been described: SFT on user chats, distillation, and preference data preparation, all powered by user interactions.
5. The Challenge of RL for Open-Ended Creative Dialogue
Next, the focus moves to RL work.
The core challenge: Aligning models for open-ended dialogue, where:
- There is no single “verifiable” reward (no exact ground truth label).
- Rich user interaction logs exist, but labels like “good story” or “helpful advice” are inherently subjective.
Reinforcement learning can be used to:
- Continuously enhance model quality,
- Drive user engagement and retention,
- While keeping manual data labeling efforts reasonable.
Training Framework
An RL training framework:
- Can be built on an internal orchestration / workflow system tightly integrated with internal data processing stacks.
-
On top of this:
- User-signal reward models are trained.
- Custom reward functions are designed for RL.
A core part of this RL work is reward modeling, because deciding which response is “better” is highly subjective in the dialog domain.
6. Model Evaluation
Before diving deeper into reward modeling, it’s worth asking: how can models be evaluated at all?
6.1 Offline Evaluation with Professional Writers
Professional writers and annotators can be used to evaluate generations, using a mixture of:
-
Creative writing dimensions:
- Novel contribution: does it add something new?
- Responsiveness: does it directly address the user’s request?
- Descriptive language: is the writing vivid and expressive?
- Gestures / actions: does it convey characters, actions, and scene effectively?
-
General quality metrics:
- Overall goodness / badness,
- Memory and consistency,
- Repetition and redundancy, etc.
Reward model scores can also be used as an offline proxy (more on those below).
6.2 Online A/B Testing and Engagement Metrics
Ultimately, however, what really matters is online A/B testing:
- First, safety must meet the required bar.
-
After that, the key metrics are engagement and retention, such as:
- Session count,
- Time spent.
An important caveat:
If offline metrics are optimized in isolation, the model that looks better offline might not actually improve engagement or retention when deployed in a real A/B test.
Offline metrics and reward model scores are treated as proxies, but online experiments are the final judge.
7. Reward Modeling from Engagement and Retention
For reward modeling, approaches can go beyond standard “quality” and “preference” models.
7.1 Engagement-Based Reward Models
In addition to:
- Quality reward models (judging response quality),
- User-preference reward models (predicting which response users prefer),
engagement-based reward models can be built.
These models try to predict:
-
Future number of turns A regression model that predicts how many future turns a conversation will have.
-
Whether the user continues the conversation A classifier predicting if the user will send another message.
-
Time to next response A signal about the immediacy of continued engagement.
Models can also be trained to predict longer-term retention, such as:
- Whether the user comes back the next day,
- Whether the user returns in seven days.
7.2 Performance of Engagement Models
Empirically from industry research:
- The future-turn regression model reaches about 0.56 (e.g., correlation or R²).
- The “continue conversation” classifier achieves around 75% accuracy.
- The “return next week” predictor achieves around 84%.
- Another retention predictor lands around 83%.
These are quite high accuracies, especially for retention predictions, which suggests the models may have learned:
- Some genuine patterns of user engagement,
- But also possibly some shortcut features.
This risk should be considered. However:
- As long as the model is also capturing useful signals, and
- Advantage-based RL is used (where certain compounding factors can cancel out),
it can still be beneficial. That said, retention-based rewarding is still experimental, and A/B test results for such rewards may not be finalized yet.
8. Other Signals and Combining Rewards
For some of the more objective quality dimensions (e.g., novel contribution), supervision can be obtained from LLM-judged data—using large models to annotate or compare responses.
Direct user feedback signals can also be used:
- Thumbs up / thumbs down on messages,
- Sometimes with reasons provided by the user.
There are other user signals that may not be prioritized yet if strong correlations with key KPIs are not found in data analysis.
8.1 Simple Baseline: Weighted Sum of Reward Components
A simple baseline for combining all these signals is:
- A weighted sum of different reward components, using heuristic weights.
These weights can also be learned to directly maximize a true business KPI, such as 7-day retention, using historical logs.
8.2 Multi-Objective Reward with Safety Constraints
A more sophisticated reward function is multi-objective with constraints.
- Certain aspects, such as safety, are treated as hard constraints, not just soft preferences.
- A Lagrangian formulation can be used to enforce a high safety threshold (denoted as τ).
For example:
- If a generated response’s safety score is below the threshold, the reward is forced to be a large negative value (−K).
- This effectively penalizes unsafe responses heavily in the RL algorithm.
9. RL Algorithm: PPO and the Training Loop
On the RL side, PPO (Proximal Policy Optimization) can be used, similar to the original InstructGPT / RLHF setup:
- PPO updates the policy by maximizing a clipped surrogate objective, constraining the policy update to avoid catastrophic drift.
9.1 Offline vs Online Training
A common question is: “You collect metrics online—are you doing online RL, updating weights in real time?”
The answer is: No, the training itself is offline.
A typical workflow is:
- Deploy a model online.
- Collect user interaction logs (prompts, responses, engagement behaviors).
- Use or retrain reward models based on this data.
- Run offline PPO training using logged data and reward models.
- Deploy the updated model.
- Repeat the loop: collect new data, retrain reward models, retrain policy.
This is a continuous but batched process, not fully online RL.
10. Handling Long-Horizon, Multi-Turn Dialogues
Another common question: “Conversations can be long, multi-turn, with delayed rewards. How can that be handled?”
This can be addressed in two ways:
-
Long-horizon reward models
-
Some reward models are explicitly designed to capture longer-term signals:
- Predicting the number of future turns.
- Predicting long-term retention (return next day/next week).
-
These provide more trajectory-level feedback rather than per-turn myopic rewards.
-
-
Multi-turn RL experiments
- Multi-turn RL setups can be experimented with,
- To ensure optimization for multi-step, long-horizon outcomes, not just immediate engagement.
This combination helps deal with very long, horizontal, multi-round conversations where rewards are inherently delayed.
11. Closing
To summarize, an alignment stack for open-ended dialogue models combines:
- Stable MoE training via expert-parallel gradient synchronization.
- Efficient serving with FP8 and quantization-aware training, including custom fused FP8 linear layers.
- Supervised fine-tuning on user chats using swipes as user-guided rejection sampling.
- Distillation from more capable “exclusive” models into cheaper models.
-
PPO-based RL, grounded in:
- Quality and preference signals,
- Engagement metrics (future turns, continuation),
- Retention predictions,
- Safety-aware multi-objective rewards.
This runs with an offline RL loop, iterating between deployment, data collection, reward model training, and policy updates. Handling noisy user feedback and long-horizon rewards is still an active area of experimentation, especially around retention-based rewards and multi-turn RL. Work is ongoing—both on the systems side (better FP8 kernels, more efficient training) and on the alignment side (richer reward models, better correlation with online KPIs, and safer, more engaging user experiences).
12. References
- https://research.colfax-intl.com/deepseek-r1-and-fp8-mixed-precision-training/
- Kuzmin, Andrey, Mart Van Baalen, Yuwei Ren, Markus Nagel, Jorn Peters, and Tijmen Blankevoort. “Fp8 quantization: The power of the exponent.” Advances in Neural Information Processing Systems 35 (2022): 14651-14662.
- Liu, Aixin, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao et al. “Deepseek-v3 technical report.” arXiv preprint arXiv:2412.19437 (2024).
- https://github.com/deepseek-ai/DeepGEMM